Sub Queries
It is possible to embed a SQL statement within another. When this is done on the WHERE or the HAVING statements, we have a subquery construct.
The syntax is as follows:
SELECT "column_name1"
FROM "table_name1"
WHERE "column_name2" [Comparison Operator]
(SELECT "column_name3"
FROM "table_name2"
WHERE [Condition])
[Comparison Operator] could be equality operators such as =, >, <, >=, <=. It can also be a text operator such as "LIKE".
Table
Shop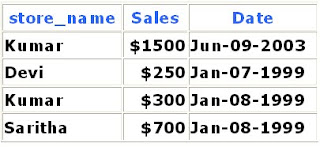
Table
Graphy and we want to use a subquery to find the sales of all stores in the South region. To do so, we use the following SQL statement:
SELECT SUM(Sales) FROM Shop
WHERE Store_name IN
(SELECT store_name FROM Graphy
WHERE region_name = 'South')
Result:
SUM(Sales)
2050
EXISTS simply tests whether the inner query returns any row. If it does, then the outer query proceeds. If not, the outer query does not execute, and the entire SQL statement returns nothing.
The syntax for EXISTS is:
SELECT "column_name1"
FROM "table_name1"
WHERE EXISTS
(SELECT *
FROM "table_name2"
WHERE [Condition])
Let's use the same example tables:
Table Shop
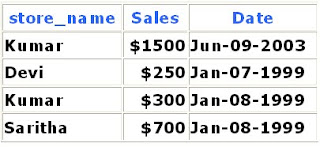
Table
Graphy
and we issue the following SQL query:
SELECT SUM(Sales) FROM Shop
WHERE EXISTS
(SELECT * FROM Graphy
WHERE region_name = 'South')
We'll get the following result:
SUM(Sales)
2750




























{kind=link}